Vanilla regression > Synthetic controls
Causal inference requires assumptions; but not all assumptions are equally plausible.

People have been doing "covariate adjustment" for estimating causal effects from observational data for many decades. It's not a perfect method, and experiments offer incontrovertible advantages, but if we are going to learn anything for the non-experimental world, regression adjustments have been and will remain an important tool.
There are other methods for doing causal inference from observational data, but most of them don't rise to the level of respectability of simple regression adjustment, in my opinion. I recently discussed this in the context of synthetic control methods, and I’m recording my thoughts here in case I want to revisit them later.
A causal inference method for non-experimental data ought to have assumptions that are justifiable in terms that make no reference to the method itself and can therefore be debated. My critique of synthetic controls as a method is that it largely fails this criteria, leading to a situation where all of the results regarding its validity, once unpacked, boil down to "it works when it works".
This is surely somewhat unfair, as any mathematical theorems boil down to tautologies. But in the case of causal inference, I think drawing the line somewhere is important as a practical matter and to my mind synthetic control methods have not met the standard of having sensible conditions where one can articulate why it is reasonable — on a case-by-case basis — to believe that they will work as desired.
As for justification of regression adjustments (in the case of observational studies) I believe that Pearl's biggest contribution (among many) is that causal diagrams give us the right vocabulary for debating — in a non-circular way! — which variables are necessary for causal inference from observational studies.
It isn't that it is reasonable to assume a full causal diagram is known (it isn't). But the ability to attempt to write one down and then debate its plausibility is a big advance over simply selecting a set of covariates and saying "these will suffice", which is effectively what invoking strong ignorability in the potential outcomes framework demands (not unlike how I claim that synthetic controls methods "work when the work").
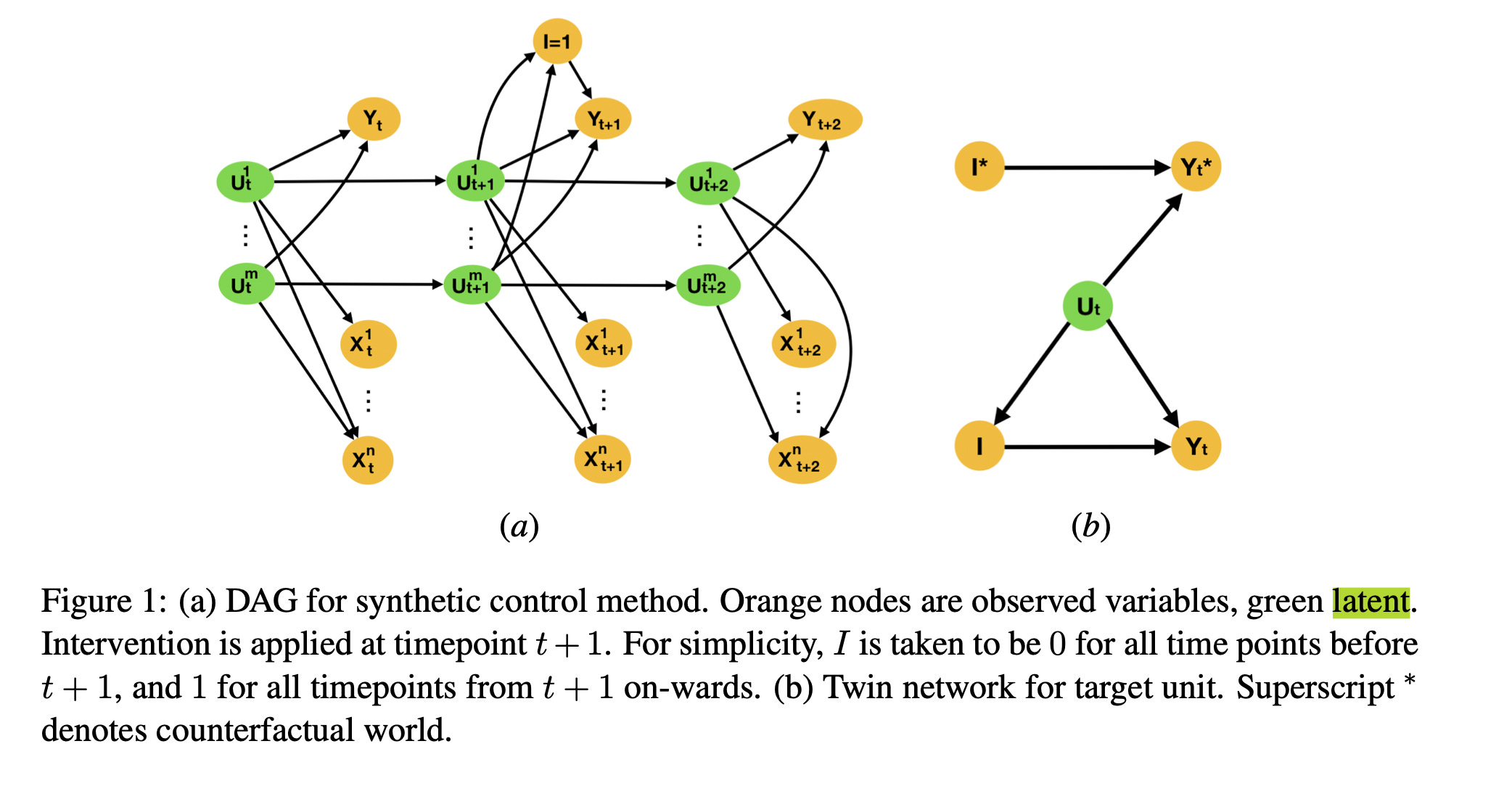
Notably, there have been papers analyzing synthetic control methods from the perspective of causal diagrams (Zeitler, et al). But notably, the key assumptions are in terms of latent, fundamentally unobserved, variables. Essentially I think causal diagrams written in terms of undefined entities are fundamentally less trustworthy than ones written in terms of known entities (whether or not we are able to measure them for the purposes of inference). See the figure from the linked paper.